When Functional Programming Isn’t

When functional programming started to become a “thing” in the software industry, I had a lot of difficulty understanding the fundamentals. I’ve always worked primarily in business application software and in system administration. The mathematical orientation of functional programming languages represented an unfamiliar paradigm for me.
I mentioned this to a colleague, and he told me that he fully grokked FP after learning to use lambda expressions in C#. His reply puzzled me, as I had been using lambda expressions in Java, Ruby, and JavaScript for some time, and I knew that similar features were present in other languages, like Python, SmallTalk, and Lisp. I had also done the usual tutorials for languages that had some Functional Programming features, like Scala and Clojure. Could it be that FP was really nothing more than this, decorated with arcane buzzwords?
Surely there was more to it. My attempts to teach myself Haskell had not gone as easily as learning other languages that were based on familiar paradigms. Haskell code was clearly quite different from lambda expressions in Java or Ruby. It seemed, instead, that support for lambda expressions in object-oriented languages had been inspired by functional languages, but that there was much more to FP than just that.
Mathematical Functional Programming
As I read more about Functional Programming, it became clear that the purpose of functional languages is to model mathematical expressions. It might have been better if the inventors of FP had named it “mathematical programming” instead. It isn’t just about writing “functions,” after all.
APL, a language developed in the 1960s, uses non-ASCII symbols in its source code to represent mathematical concepts. A special keyboard mapping was designed to support working in APL. It looks like this:

Here’s an example of Conway’s Game of Life implemented in APL, from StackOverflow:
![]()
Other functional languages, such as J, substitute ASCII symbols for mathematical symbols so that mathematical expressions can be entered using a standard keyboard. Here’s an example of Conway’s Game of Life implemented in J:
step =: ((]+.&(3&=)+)(+/@(((4&{.,(_4&{.))(>,{,~>i:1))&|.)))~
Even if you aren’t familiar with those languages, you can probably see the two code snippets are roughly similar. Personally, I find the J code harder to read, but I appreciate the practicality of being able to enter source code with a standard keyboard.
One of the key uses of mathematical expressions is to process lists or series, like this formula for calculating the area under a curve (image borrowed from here):
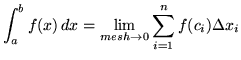
So, there’s an integral and a summation and so forth. Functional programming languages are designed to solve this sort of problem efficiently based on concise source code. The language may have a number of these common calculations built in or available through libraries.
Lambda expressions in object-oriented languages serve the same purpose. The examples we find online can be confusing for a business application programmer because we don’t often face mathematical problems. Programmers who write data analytics code and those who work on scientific/engineering solutions will find the usual examples more relatable.
In business application programming we do quite often process collections of objects, either filtering a subset of members, combining two collections, or performing an operation on all members (like map and reduce operations). Lambda expressions often enable us to express these operations in a concise and readable way, as compared with (for instance) nested for loops. The code also tends to be less error-prone than a complicated loop structure.
For example, here’s an iterative solution to the Fibonacci series in Java (snagged from a StackOverflow question):
public int fib(int n) {
int x = 0, y = 1, z = 1;
for (int i = 0; i < n; i++) {
x = y;
y = z;
z = x + y;
}
return x;
}
For constrast, here’s a solution using lambda expressions (thanks to Artem Lovan):
public static List generate(int series) {
return Stream.iterate(new int[]{0, 1}, s -> new int[]{s[1], s[0] + s[1]})
.limit(series)
.map(n -> n[0])
.collect(toList());
}
(Yes, I was lazy and didn’t write my own examples. How different could they have been, anyway?)
You can see for yourself that the lambda version is more concise and expresses its intent effectively.
Practical take-aways for general software development
Is it true that when you’ve mastered lambda expressions in an OO language, you’ve also mastered functional programming? I don’t think so. But I do think it’s a good idea to master lambda expressions.
General business application programming has taken several ideas from Functional Programming that improve our software design. These include (at least):
- avoid hidden side-effects
- ensure referential transparency
- use list-processing functions rather than loops where it makes sense
Those guidelines are not really different from conventional OO design guidelines. Avoiding hidden side-effects is another way to express the idea of separation of concerns or single responsibility principle. When you do that, you also achieve referential transparency. Lambda expressions that operate on collections make the code more expressive of intent and more concise. It has always been a goal of OO design to make the code expressive of intent.
Microtests
Contemporary development practices include the idea of microtests, which are very small examples of functionality that exercise (in an OO language) a single logical path through a single method. They are often used to support emergent design through test-driven development as well as to explore the functionality of an existing code base by probing it with small test cases.
When I use lambda expressions in an OO language, I find that the smallest logical chunk of code that can be exercised by a micro-example is larger than when I use iteration or recursion for the same solution. Let’s look at the two Java examples above, and write microtests for them.
If we take that iterative example and flesh it out a bit so that we can obtain a Fibonacci series, we get this:
public class FibIterative {
public int fib(int n) {
int x = 0, y = 1, z = 1;
for (int i = 0; i < n; i++) {
x = y;
y = z;
z = x + y;
}
return x;
}
public List<Integer> fibSeries(int limit) {
List<Integer> result = new ArrayList<Integer>();
for (int i = 0 ; i < limit ; i++ ) {
result.add(fib(i));
}
return result;
}
}
Some microtests for that code could look like this:
@Test
public void the_2nd_value_is_1() {
assertEquals(1, fib.fib(1));
}
@Test
public void the_5th_value_is_3() {
assertEquals(3, fib.fib(4));
}
@Test
public void first_10_values() {
List expected = Arrays.asList(new Integer[] { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 });
assertEquals(expected, fib.fibSeries(10));
}
The key point here is that the smallest chunk of logic we can check is the code that determines the next number in the series. The third example shows that we could verify the functionality by checking the entire list. However, if there is an error in the single-number routine the whole-list check won’t take us directly to the offending line in the source. (You may have to imagine something more complicated than this to visualize the problem.) There are special rules for the first few numbers in the Fibonacci series, and that’s where an error is most likely.
An advantage of using a lambda expression is that the correctness of the series can be assured by the lambda expression itself. The smallest microtest example we need is one that covers the whole series.
Adjusting the sample lambda solution so it will compile, and making the method non-static, we have this:
public class FibLambda {
public List generate(int series) {
return Stream.iterate(new int[]{0, 1}, s -> new int[]{s[1], s[0] + s[1]})
.limit(series)
.map(n -> n[0])
.collect(Collectors.toList());
}
}
You can already see a couple of advantages, even before we consider the microtests. This solution involves less code, and therefore less probability of an error occurring. The code is also a little more self-describing.
We don’t need microtest examples to verify that individual numbers in the series will be calculated correctly, as that is baked into the lambda expression. We only need to verify that the series comes out as expected. So, we have fewer test cases to maintain, without getting into the ice cream cone anti-pattern of test automation.
@Test
public void it_generates_the_first_10_values() {
List expected = Arrays.asList(new Integer[] { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 });
FibLambda fib = new FibLambda();
assertEquals(expected, fib.generate(10));
}
Programmer effectiveness in Functional Programming
It takes a programmer about the same amount of time and effort to read/understand, design/create, comprehend/modify a line of source code regardless of the programming language involved. When a language offers more power per source expression, solutions can be built using fewer lines of code. Programmers’ time is used more effectively than when they must write in a language that doesn’t offer much power per expression.
Functional languages pack a lot of power into each line of source code. When we use elements borrowed from Functional Programming in our OO languages, we can gain some of those benefits, too.
To illustrate, here are some code snippets that sum the values in an array. First, let’s look at Intel assembly language. This example is borrowed from here.
; find the sum of the elements of an array
SECTION .data ; start of data segment
global x
x:
dd 1
dd 5
dd 2
dd 18
sum:
dd 0
SECTION .text ; start of code segment
mov eax,4 ; EAX will serve as a counter for
; the number words left to be summed
mov ebx,0 ; EBX will store the sum
mov ecx, x ; ECX will point to the current
; element to be summed
top: add ebx, [ecx]
add ecx,4 ; move pointer to next element
dec eax ; decrement counter
jnz top ; if counter not 0, then loop again
done: mov [sum],ebx ; done, store result in "sum"
So, we have 21 lines of source code to understand and maintain. Due to the nature of the language, we also have to include quite a few source comments to communicate the intent of the code. Those things increase the time and effort programmers must expend to live with this solution. The dependence on comments introduces a risk that the comments and code will no longer match, after the solution has been modified during its long years of production life.
The equivalent code in Java, using iteration to sum the values, looks like this:
public int sumArrayIterative(List myFineList) {
int sum = 0;
for (Integer value : myFineList) {
sum += value;
}
return sum;
}
That’s seven lines (four of which are “meat”), which is a lot more understandable than 21 lines. We don’t need any source comments to explain the intent of the code, either.
Now let’s do the same thing using a lambda expression.
public int sumArrayStream(List myFineList) {
return myFineList.stream().mapToInt(i -> i).sum();
}
Using a lambda expression reduces the number of source lines to three (two of which are “meat”). It makes programmers’ time just a little bit more impactful, and makes the code just a little bit more habitable in the functional programming.
Another advantage: Those “non-meat” lines in source code are clutter that makes it harder to follow what the code is doing. With the Java iterative solution, almost half the source lines are clutter. With the lambda solution, there’s only one line of clutter, and it’s nothing more distracting than a closing curly brace.
Learning resources
Martin Fowler has written a very clear introduction to collection pipelines, which are in essence what we are writing when we use the lambda expression features of OO languages. That article contains numerous examples in several languages.
He also wrote a step-by-step guide to refactoring a loop into a collection pipeline in a way that safely preserves behavior at each step. I suggest this is a useful skill to practice in a dojo setting or on your own.
The ever-practical Brian Marick has been spending considerable time delving into Functional Programming in the past couple of years. He has shared his learning journey on Twitter, and has produced a couple of very useful e-books that can help a general software developer get a handle on Functional Programming.
Functional Programming for the Object-Oriented Programmer and An Outsider’s Guide to Statically-Typed Functional Programming introduce Functional Programming in a way an everyday software development practitioner can relate to, as opposed to the abstract approach offered by most other sources. The latter book seems to have offended some in the FP community for reasons I don’t understand. In any case, these are great resources for learning about FP, if you’re already an experienced OO developer.
Conclusion
Using lambda expressions in an OO language doesn’t make you a functional programmer, but using ideas from the Functional Programming community to produce clean OO code is a Good Thing. OO code that uses a functional style will tend to have fewer problems of the kinds that arise from hidden side effects and poor separation of concerns. Lambda expressions are readable and expressive of intent for sections of code that process lists or collections; often moreso than iteration. In Java, for instance, using the explicitly-defined functional interfaces helps us produce reliable code that is compatible with other useful design techniques such as immutable objects.
Comments (11)
L N. Brown
Your example is a little bit flawed:
The 21 lines of assembly have 3 “non-meat” (comment only) lines and 5 lines to set up the list the other examples do not have.
The java example is about summing up a list, which every programmer understands.
The lambda example? It uses a function call sum(). Which itself is probably coded just as the java example. You are just on another level of detail or abstraction.
What makes the lambda example much worse:
It is quite clear to call sum() on a list. But stream() and mapToInt()? This leaves way too much questions …
My conclusion: No, the lambda example is not easier to understand. It hides a lot of information.
jeff
I agree with LN Brown. Also, I don’t agree that the non-FP fibonacci algorithm is more complex. Fewer lines does not necessarily mean simpler. Your premise about FP and developer efficiency is correct; you just haven’t demonstrated it.
Can you suggest an example that would demonstrate the point more effectively?
Re the Fibonacci example…what struck me about the different implementations was that the lambda version could be driven out with fewer microtests, and supported by fewer regression test cases, than the other implementations. If we extrapolate to a large codebase and imagine ourselves maintaining that code and its test suites, then a small savings in the number of discrete cases could translate into substantial saved effort and reduced risk of error in the long term. Just something to consider.
I second-guessed myself about using the assembly example for the same reason. On the other hand, in your comment you write “just on another level of…abstraction.” The word, “just” can be problematic. The level of abstraction can be important. Lambda expressions let us write certain kinds of statements concisely, which may be helpful (or may not be, as you conclude regarding ease of understanding). Regarding the specific methods, stream() and mapToInt() are Java-specific, so I wouldn’t necessarily expect someone to understand what they’re doing the first time they saw them, if they weren’t into Java; but not because they’re used in a lambda expression. I’m not sure they’re any harder to understand than most source statements in most languages, generally. In some contexts I would agree with you about high-level statements hiding information. Hopefully what they hide are implementation details that aren’t necessary to understanding the logic of the routine. Sometimes they hide more than that, unfortunately. Thanks for the feedback!
Nick
I do not personally see the functional lines to be easier to read at all.
As said some pieces are not equivalent neither.
Now leaving the preference for vs functional calls apart,
There seems to be a confusion between few different things coming back recurrently in the FP fans that i disagree with.
one of them is “Shorter” is not at all the same as “Simpler”. And while a code might be shorter or convenient to write in the moment
it can be at the detriment of the later readability, clarity, and maintenance.
In real world it is harder (I do not think just for me) to read/understand some code when a block consists in one single gigantic block of 20 lines consisting of ONE instruction embedding non named blocks, anonymous functions, and sub calls, with sometimes no explicit types on top of it.
The fact to HIDE your sub functions ANONYMOUSLY you now have to GUESS what the pieces do because of they have no explicit name attached. Functions are not declared, variables are not declared, types are not explicitly declared,… If you miss guess one part of the logic you have no clues neither to help you figure out.
Anonymous code is not better, while it is indeed shorter.
Breaking down a big block into smaller pieces is usually not a bad thing!
Another problem is with debugging.
You can debug a loop and even it can help you understand what s going on
but how do you debug a pile of things like:
x.iterate(expr1).func1().map(expr2)…………..collect(Collectors.toList());
well you CAN NOT unless you rewrite for debug purposes.
pragmatically now…
a code with for loops and declared types functions, i am confident many developers could unserstand and change it.
what about an esotheric one liner? Can you honestly say yes this is as easy or safe for anyone to maintain?
So far my experience from real life projects is that:
– dependency injection “AOP” non explicit calls
and
– functional shorter but more complex to read blocks of code
are not good ideas in practice unless you have a good reason for it.
But yes they save you a line or two of syntax.
Josh Yates
Functional/Mathematical programming such as Haskell appears to be a choice for building an Infrastructure (or Platform) such as Cardano’s blockchain. Solid choice!
With the choices of higher level programming languages in order to build an application at the rate where software has engulfed the world, FP appears not needed. WebAssembly coming soon…
Kirk Hawley
“You can see for yourself that the lambda version is more concise and expresses its intent effectively.”
It seems strange to me that you would use a block containing nothing but one-letter variables as a comparison, and then attribute the difficulty of reading it to not using lambda expressions.
Then I should say, “You can see for yourself whether you think the lambda version is more concise and expresses its intent effectively.” Can you suggest a more effective example?
Alistair Bayley
Who has “the outsiders guide…” offended, and how? References pls.
Nick Dunets
FP is just as mathematical as SQL is. For a random person abstract reltational algebra (basis of SQL) can be just as confusing as Category Theory (basis of pure FP). However nobody who knows SQL will tell that it’s good only for mathematical problems and useless for some business domain because it’s nonsense.
FP is good for domain design just as much as for math, there are multi-billion businesses (e.g. jet.com) that use FP as a tool of choice and think of it as competitive advantage, books about using FP in business domains (e.g. Domain Driven Design made Functional), ongoing revolution in mainstream front end development based on FP ideas.